
Knowledge Tracing for Complex Problem Solving Granular Rank-Based Tensor Factorization
2025-05-03
0
0
1.48MB
16 页
10玖币
侵权投诉

Knowledge Tracing for Complex Problem Solving: Granular Rank-Based
Tensor Factorization
CHUNPAI WANG, University at Albany - SUNY, USA
SHAGHAYEGH SAHEBI, University at Albany - SUNY, USA
SIQIAN ZHAO, University at Albany - SUNY, USA
PETER BRUSILOVSKY, University of Pittsburgh, USA
LAURA O. MORAES, Federal University of Rio de Janeiro, Brazil
Knowledge Tracing (KT), which aims to model student knowledge level and predict their performance, is one of the most important
applications of user modeling. Modern KT approaches model and maintain an up-to-date state of student knowledge over a set of
course concepts according to students’ historical performance in attempting the problems. However, KT approaches were designed
to model knowledge by observing relatively small problem-solving steps in Intelligent Tutoring Systems. While these approaches
were applied successfully to model student knowledge by observing student solutions for simple problems, such as multiple-choice
questions, they do not perform well for modeling complex problem solving in students. Most importantly, current models assume that
all problem attempts are equally valuable in quantifying current student knowledge. However, for complex problems that involve
many concepts at the same time, this assumption is decient. It results in inaccurate knowledge states and unnecessary uctuations
in estimated student knowledge, especially if students guess the correct answer to a problem that they have not mastered all of its
concepts or slip in answering the problem that they have already mastered all of its concepts. In this paper, we argue that not all
attempts are equivalently important in discovering students’ knowledge state, and some attempts can be summarized together to better
represent student performance. We propose a novel student knowledge tracing approach, Granular RAnk based TEnsor factorization
(GRATE), that dynamically selects student attempts that can be aggregated while predicting students’ performance in problems and
discovering the concepts presented in them. Our experiments on three real-world datasets demonstrate the improved performance of
GRATE, compared to the state-of-the-art baselines, in the task of student performance prediction. Our further analysis shows that
attempt aggregation eliminates the unnecessary uctuations from students’ discovered knowledge states and helps in discovering
complex latent concepts in the problems.
CCS Concepts:
•Social and professional topics →Student assessment
;
•Computing methodologies →Tensor factorization
.
Additional Key Words and Phrases: knowledge tracing, tensor factorization, complex problem solving, aggregation
ACM Reference Format:
Chunpai Wang, Shaghayegh Sahebi, Siqian Zhao, Peter Brusilovsky, and Laura O. Moraes. 2021. Knowledge Tracing for Complex
Problem Solving: Granular Rank-Based Tensor Factorization. In Proceedings of the 29th ACM Conference on User Modeling, Adaptation
and Personalization (UMAP ’21), June 21–25, 2021, Utrecht, Netherlands. ACM, New York, NY, USA, 16 pages. https://doi.org/10.1145/
3450613.3456831
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not
made or distributed for prot or commercial advantage and that copies bear this notice and the full citation on the rst page. Copyrights for components
of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to
redistribute to lists, requires prior specic permission and/or a fee. Request permissions from permissions@acm.org.
©2021 Association for Computing Machinery.
Manuscript submitted to ACM
1
arXiv:2210.09013v1 [cs.CY] 6 Oct 2022
UMAP ’21, June 21–25, 2021, Utrecht, Netherlands Wang, et al.
1 INTRODUCTION
Personalized online learning systems have recently drawn a lot of attention because of the growing need to assist and
improve students’ learning. A fundamental part of the user modeling task in these systems is estimating students’
knowledge states as they work with learning materials [
3
]. This task, known as knowledge tracing (KT), is necessary for
predicting students’ performance in future assessments, personalizing problems and exercises for students, identifying
at-risk students, and providing teachers with a detailed view of overall student progress. In particular, KT models use
student attempt sequences, including student performance (e.g., success or failure) on past problems, to estimate student
knowledge at the end of a sequence and predict student performance on the next attempts.
To quantify student knowledge, traditional KT models rely on a predened domain knowledge model that represents
the associations between the problems and course concepts. Such models individually trace student knowledge in each
of these concepts, neglecting the potential relationships between dierent concepts. As these models learn the same set
of parameters for all students, they are not personalized to the student specications. For example, Bayesian knowledge
tracing (BKT) [
3
], which is one of the pioneer KT models, represents student knowledge states in each concept using a
two-state HMM, which imposes a Markovian assumption on knowledge states from one attempt to the next.
In recent years, modern KT models have been developed to address the above problems. For example, many variants of
BKT have been proposed to improve the model by considering the potential to forget the learned concepts [
7
], accounting
for the dependencies between concepts [
8
], and personalizing the model parameters for dierent students [
27
]. In addition
to the Bayesian models, latent factor approaches have been successful in considering the concept relationships [
11
,
20
,
21
,
29
]. For example, Lan et al. [
11
] proposed a sparse factor analysis framework for both student knowledge tracing
and domain knowledge estimation. Sahebi et al. [
20
] proposed a tensor factorization method to explicitly model student
learning processes by assuming a strictly monotonic increasing learning gain. Zhao etal. [
29
] leverage the multiview
tensor factorization method for modeling student knowledge using multiple learning resource types. Similarly, deep
learning models, such as DKT [17] and DKVMN [28], have recently been introduced into the KT domain.
However, the majority of KT models have assumed that each attempt in a sequence considered by tracing is relatively
simple and involves the application of one or very few concepts, such as small steps in solving either a complex problem
or an elementary problem. With this assumption, the observed student performance can be directly associated with a
few involved domain concepts, and each correct or incorrect attempt by the student can provide a relatively condent
evaluation of student knowledge in those concepts. As a result, when considering these kinds of problems, current
KT models assume that every attempt in student history is equally important in quantifying student knowledge. This
assumption can be sucient for domains in which each problem consists of a few atomic concepts. However, it is
decient for domains with more complex problems, such as writing a program or solving an assignment with multiple
steps.
In complex problem solving, each problem can include multiple concepts, such that knowing all of them to some
extent is necessary for correctly answering the problem. Because of this complexity, student attempt observations will
be noisier, as slipping in even one of the required concepts can signicantly harm student performance. Additionally,
identifying the concepts that are responsible for an imperfect performance will be more challenging in such complex
problems. Similarly, solving a complex problem correctly by guessing a dicult unknown concept or by trial and error
on that important concept will be wrongly attributed to a student’s high knowledge of all of the involved concepts. As
a result, such noisy observations could easily cause traditional KT models to provide an inaccurate estimation of overall
levels of student knowledge. For example, consider a student who has already mastered some concepts. This student
2
Knowledge Tracing for Complex Problem Solving: Granular Rank-Based Tensor Factorization UMAP ’21, June 21–25, 2021, Utrecht, Netherlands
tries a problem on those concepts three times, getting the problem right the rst time (successful attempt), slipping in
one of the concepts the second time (failed attempt), and getting it right again in the third time (successful attempt). In
current KT approaches, since the model tries to t every student attempt, these cases result in uctuations in estimated
student knowledge. Even in models like BKT, which try to consider small guess and slip probabilities by modeling each
concept independently, or DKT+ [
26
], which aims to smooth out student predicted performance (not knowledge) using
a constraint, having a binary knowledge state and tting to every attempt results in knowledge state inaccuracies.
In this paper, we argue that, due to the noise in solving complex problems, some student attempt observations
are more informative and important than others. For that, we address the student knowledge tracing challenge for
complex problems by summarizing student attempts to better represent student performance. We propose a personalized
knowledge tracing model that automatically detects “less important” student attempts and aggregates them into other
attempts to better represent student knowledge and predict their performance. Additionally, our proposed KT model is
personalized for students and automatically discovers the domain knowledge model without requiring extra problem
information, such as text, topics, or tags. In particular, we model student sequences in a tensor and propose an adaptive
Granular RAnk based TEnsor factorization (GRATE) to address the noisiness and sparsity issues so as to provide a
plausible and precise knowledge modeling. We impose a rank-based constraint on student knowledge across attempts to
help reduce the unnecessary uctuations in student knowledge and improve the interpretability of the model. GRATE
does not rely on a domain knowledge model, as it automatically discovers latent concepts for the problems presented to
students. It is personalized by proling students into student latent features and learning a separate set of parameters
for them in a collaborative way.
Our contributions in this paper are:
(a)
, we are the rst to address the noisy observation challenge for student
knowledge tracing in complex problem solving;
(b)
, for this, we propose a novel tensor factorization method that
adaptively aggregates student attempts while imposing a rank-based constraint to represent students’ gradual learning;
(c)
, our knowledge tracing model is personalized and does not rely on additional domain knowledge information;
(d)
,
we conduct extensive experiments to analyze and validate the eectiveness of our proposed model, compared to several
state-of-the-art baselines, on three real-world datasets; and
(e)
, we demonstrate that our proposed method is capable of
providing precise and plausible student knowledge states while learning meaningful question-concept associations.
2 GRANULAR RANK BASED TENSOR FACTORIZATION (GRATE)
Our goal in this work is to handle the noise and uctuations in student knowledge tracing of complex problems without
relying on a domain knowledge model or a predened mapping between problems and concepts. We aim to do this
with a personalized KT approach that is interpretable without harming the model performance; e.g., in the student
performance prediction task. In the following, we formulate this challenge as a tensor factorization problem, present
our proposed method to address the challenge, explain our intuition behind choosing tensor factorization as the basis
of our model, and provide the algorithm for our method.
2.1 Problem Formulation and Assumptions
We consider an online learning system in which
M
students attempt
N
problems in sequences of maximum length
T
over time. Students can attempt the problems in any order and as many times as they like. Student performance
during each attempt is recorded as a score, grade value, or binary (success or failure) data. We represent the students’
logged performance records in a 3-mode tensor
X∈ [
0
,
1
]M×T×N
. Every entry
𝑥𝑢,𝑡,𝑖 ∈X
represents the
𝑢𝑡ℎ
student’s
normalized grade on
𝑖𝑡ℎ
problem at attempt index
𝑡
. Our goal is to factorize this tensor to be able to accurately estimate
3
UMAP ’21, June 21–25, 2021, Utrecht, Netherlands Wang, et al.
student knowledge of the problems’ latent concepts and predict student performance in their future problem attempts,
according to their history.
Model Assumptions.
We build our model based on the following assumptions:
(a)
Domain knowledge assumption:
Each problem covers a number of concepts that are presented in the course with dierent proportions; the set of all of
the course concepts are shared across problems; and the training data does not include the problems’ contents nor their
concepts.
(b)
Student performance assumption: Dierent students have dierent learning abilities and initial knowledge
and their performance in dierent problems depends on their knowledge state, especially in the concepts related to
those problems.
(c)
Student learning assumption: As students interact with the problems, they learn the concepts that
are presented in them, meaning that their knowledge in these concepts increases gradually; but students may also
forget some concepts.
(d)
Attempt noisiness assumption: Student data can be noisy; e.g., they may slip in one concept out
of all the problem concepts and receive a low score, while they have already mastered all of these concepts. Similarly,
they may guess the correct answer to a problem without knowing all the problem concepts. As a result, some attempts
may not be an accurate representation of student knowledge.
2.2 The Proposed Model
Tensor Factorization.
Following the (a) domain knowledge and (b) student performance assumptions above, we rst
model student interaction tensor
X
as a factorization of three lower dimensional representations: 1) an
M × K
student
latent feature matrix
𝑆
, that represents particular student features (such as abilities and personalities) that are constant
over time; 2) a
K × T × C
temporal dynamic knowledge tensor
A
, that shows the knowledge of students with specic
abilities in the course concepts as they attempt the problems; and 3) a
C × N
matrix
𝑄
serving as a mapping between
problems and course concepts. The upper tensor factorization in Figure 1represents this model. According to our
factorization, the resulting tensor from product
K=𝑆A
represents student knowledge in each concept at each attempt.
In addition to the above factors, we add a student-specic bias
𝑏𝑢
, problem-specic diculty
𝑏𝑖
, and average score
oset
𝜇
. Consequently, we can estimate students’ performance at attempt
𝑡
as in the following, where
𝜎
represents a
standard probit or logit link function:
ˆ
𝑥𝑢,𝑡,𝑖 =𝜎(s𝑢·𝐴𝑡·q𝑖+𝑏𝑢+𝑏𝑖+𝜇)(1)
Note that using
𝜎
makes the model interpretation exible: both as an estimation of a real-valued score between zero
and one, and as the probability value of the binary success or failure in solving a problem (as in a classier). To learn
the parameters 𝑆,𝐴,𝑄, and the biases, we can minimize the following objective function:
L0=
𝑢,𝑡,𝑖 ∈𝛺𝑜𝑏𝑠 𝑥𝑢,𝑡,𝑖 −ˆ
𝑥𝑢,𝑡,𝑖 2+𝜆𝑠∥𝑠𝑢∥2
2+𝜆𝑎
T
𝑡=1
∥𝐴𝑡∥2
𝐹(2)
in which the set
𝛺𝑜𝑏𝑠
consists of all non-missing values in
X
. The last two terms are regularization constraints with
important weights 𝜆𝑠and 𝜆𝑎to ensure the generalizability of the learned values.
Adaptive Granularity-Based Aggregation.
The student attempt tensor
X
is very sparse, since the students only
interact with one problem during each attempt. Additionally, because of problem complexities, the observed attempts
are noisy and unreliable (assumption (d) or attempt noisiness assumption). As a result, it is dicult to extract accurate
and interpretable underlying structures from this tensor. Moreover, equally relying on all attempts, whether they are
noisy or not, results in imprecise knowledge states and poor performance predictions.
4

摘要:
展开>>
收起<<
KnowledgeTracingforComplexProblemSolving:GranularRank-BasedTensorFactorizationCHUNPAIWANG,UniversityatAlbany-SUNY,USASHAGHAYEGHSAHEBI,UniversityatAlbany-SUNY,USASIQIANZHAO,UniversityatAlbany-SUNY,USAPETERBRUSILOVSKY,UniversityofPittsburgh,USALAURAO.MORAES,FederalUniversityofRiodeJaneiro,BrazilKnowle...
声明:本站为文档C2C交易模式,即用户上传的文档直接被用户下载,本站只是中间服务平台,本站所有文档下载所得的收益归上传人(含作者)所有。玖贝云文库仅提供信息存储空间,仅对用户上传内容的表现方式做保护处理,对上载内容本身不做任何修改或编辑。若文档所含内容侵犯了您的版权或隐私,请立即通知玖贝云文库,我们立即给予删除!
相关推荐
-
2021 年全国硕士研究生入学统一考试英语(一)试题及参考答案VIP免费

 2024-12-02 4
2024-12-02 4 -
2016年一级注册消防工程师消防安全案例分析VIP免费
 2024-12-03 7
2024-12-03 7 -
2017年注册消防工程师案例分析真题解析VIP免费
 2024-12-03 4
2024-12-03 4 -
2015年注册消防工程师案例真题解析VIP免费
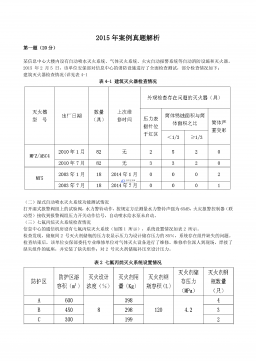 2024-12-03 35
2024-12-03 35 -
2019年注册消防工程师案例分析真题解析VIP免费
 2024-12-03 39
2024-12-03 39 -
消防综合能力真题按章节版(2015-2019年)VIP免费
 2024-12-03 17
2024-12-03 17 -
消防技术实务真题按章节版(2015-2019)VIP免费
 2024-12-03 15
2024-12-03 15 -
2018年注册消防工程师案例分析真题解析VIP免费
 2024-12-03 28
2024-12-03 28 -
2006年中央、国家机关公务员录用考试行政职业能力测试真题及答案解析(A类)【完整+答案+解析】VIP免费

 2024-12-13 121
2024-12-13 121 -
2008年0706河南公务员考试《行测》真题VIP免费
 2025-02-25 14
2025-02-25 14
分类:图书资源
价格:10玖币
属性:16 页
大小:1.48MB
格式:PDF
时间:2025-05-03
作者详情

相关内容
-

2007年天津市公务员考试《行测》真题(春季卷)答案及解析
分类:
时间:2025-02-07
标签:无
格式:PDF
价格:5.9 玖币
-

2005年江苏省公务员考试《行测》真题(B类卷)答案及解析
分类:
时间:2025-02-07
标签:无
格式:PDF
价格:5.9 玖币
-

2010年广东公务员考试《行测》真题(部分题目缺失)
分类:
时间:2025-02-25
标签:无
格式:PDF
价格:5.9 玖币
-

2010年北京公务员考试《行测》真题
分类:
时间:2025-02-25
标签:无
格式:PDF
价格:5.9 玖币
-
2008年0706河南公务员考试《行测》真题
分类:
时间:2025-02-25
标签:无
格式:PDF
价格:5.9 玖币

